
Predictive maintenance is a process designed to help determine the condition of a machine in use to estimate when maintenance should occur. This practice, which employs IoT, edge computing, and data analytics, has the potential to save industrial enterprises operational costs by reducing the number of machines that go out of service unexpectedly. Predictive maintenance also eliminates the need for unnecessary maintenance checks on perfectly healthy machines.
To help explain how an intelligent predictive maintenance pipeline would work, we will use the example of a company we created called Kanarra.
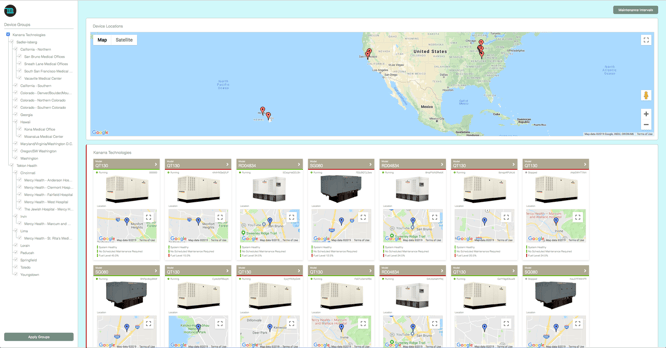
Kanarra has hundreds of generators across the country that provide power to hospitals. Kanarra collects telemetry data, e.g. temperature, vibration, motor speed and fault codes from their generators. Over time, Kanarra has gathered a significant number of data points and they would like to use the data for predictive maintenance.
Kanarra has been gathering and storing telemetry data for a long time, but now Kanarra uses the Losant Edge Agent to collect data from each generator to send to Losant for Application Enablement. The overarching goal is to predict when a generator is about to produce a fault code. Then, after a prediction is made, they would like the machine to automatically notify the company’s service partners, and assign the task to someone before the fault code results in a failure. Having this process in place saves Kanarra money by saving generators from shutting down completely, which will also provide a better experience for their customers.
In this article, we will look at how the company Kanarra would build a predictive maintenance pipeline using TensorFlow and the Losant Edge Agent.
Obtaining the TensorFlow Model
First, in order to accurately predict an action, Kanarra must have a significant amount of data. To predict when a generator is about to produce a fault code, Kanarra must develop a machine learning algorithm using the historical data of all their generators.
In this case, Kanarra is going to use a TensorFlow model to help develop this algorithm. There are several steps to accomplish before Kanarra can begin to make predictions.
Collecting Data to Train the TensorFlow Model
Kanarra has been collecting telemetry data for a number of years. The team has plenty of data points from its machines including vibration, motor temperature, and fault codes. Here are what some of those attributes look like in Losant:
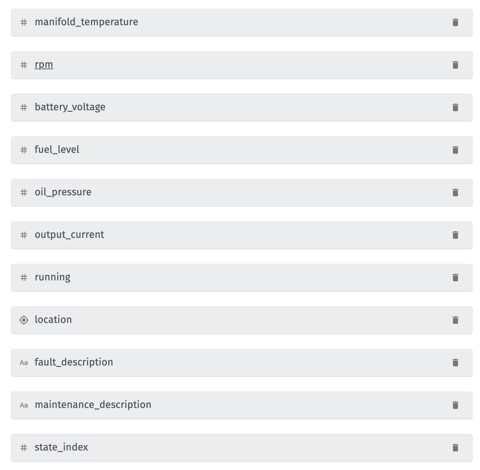
Kanarra also has information about the conditions around the machines. This includes humidity, temperature, the length of time a machine has been running and how often a machine gets restarted. These data points can be used for a set of training data and a set of testing data.
Making A TensorFlow Model
Next, Kanarra’s data scientist has to create a TensorFlow model that will use the machine’s telemetry data (vibration, temperature, speed, etc.) to output the possibility (a percentage) that this machine would fail and produce a fault code in the near future. The model is extremely important as it will be making the predictions. If the output is zero percent, this means it is currently not going to fault. On the other hand, one hundred percent means that there is a high chance it is going to fault at any second.
Once Kanarra’s team obtained their model, they were able to upload it onto their Losant Edge Agent. Particularly for their usage within Losant, the TensorFlow model Kanarra created is a TensorFlow JS model, which is supported by the TensorFlow: Predict Edge Node.
In practice, it’s very popular to build a model using the Python version of TensorFlow. However, at the time of writing, the Losant’s Edge Agent only allows for JavaScript TensorFlow models. If a model is built using the Python version, it can be converted before usage within the Edge Agent.
Verifying Model Accuracy
Model verification is the best way to tell if Kanarra’s predictions will be accurate. Predictions are only useful if they are accurate. If they are not accurate, Kanarra will end up with a lot of false positives (e.g. Kanarra would end up having a lot of extra maintenance calls that are unnecessary).
Kanarra was able to verify their model using the following process:
- First, the data scientists aggregated all of their historical data across all generators and randomized it.
- Second, the team split the data into two groups: training data and testing data. In their case, they used 80 percent of their data for training the model, while 20 percent was left over to test their model. Kanarra cannot test the model with the data they trained with, otherwise, they will end with false accuracy.
- Third, after training, Kanarra’s team tested their model by making predictions from the testing data. After many iterations, the team found that they accurately predicted the historical output. For example, if Kanarra’s accuracy came out to 95 percent accurate, that means that only five percent of the time they will get a false positive.
As Kanarra continues to collect data, they can integrate it into this process and continue to make more and more accurate predictions.
Integrating the Model With Losant
Now that Kanarra has created a model, and they know it’s accurate for the job, they are ready to put the model onto their Edge Agents.
Here is how it works:
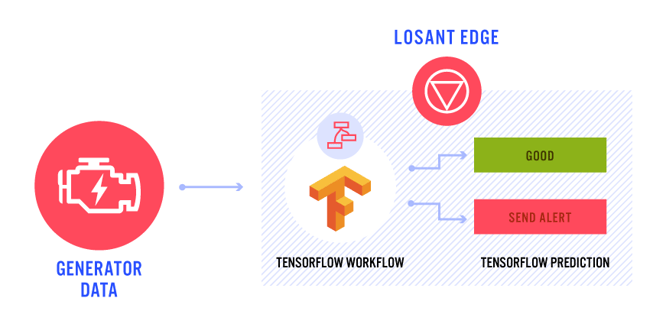
As the generator is running, an Edge Workflow is collecting the telemetry data from the machine. Then, locally, on the edge, the model can be used within an Edge Workflow. This allows the team to build a conditional if the models detect a failure to notify the company’s service partners and/or create a service ticket.
Installing the Model Onto the Edge Agent
To get the model on the Edge Agent, first Kanarra downloaded the model and the weights file into the Gateway that is running the agent. Once on a gateway, the directory containing the model should be a mounted volume specified in their configuration when starting the Docker container.

Building the Edge Workflow
Before using the TensorFlow Node, here is what the Edge Workflow looked like to collect data from a generator:
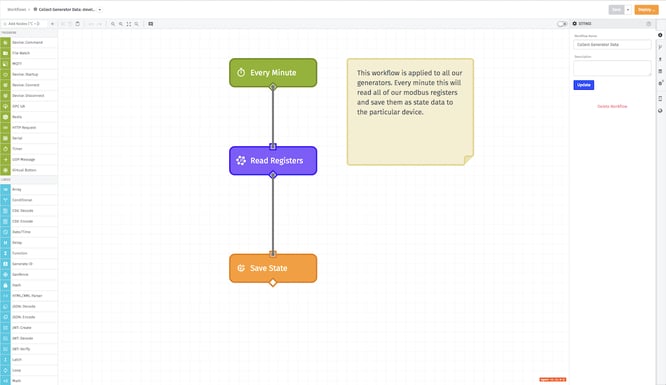
The current workflow is very simple. It is a Timer Trigger, a Modbus: Read Node, and a Device State Node. Every thirty seconds, when this workflow is triggered, it will read the Modbus registers of the PLC located on the generator and store the result data as device state.
With this workflow, it requires only two nodes to make predictions: The TensorFlow: Predict Edge Node and a Conditional Node. Here is an example:
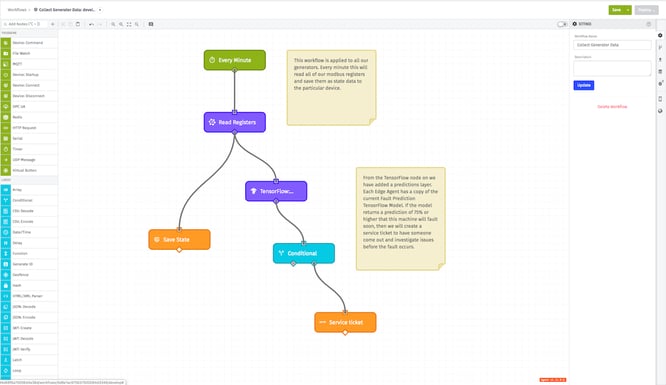
In this workflow, the team can make the prediction that if the percentage likelihood to fault is higher than 75 percent, a ticket will be created to allow a maintenance staff member to assess the generator. To achieve this, Kanarra added a TensorFlow JS: Predict Node onto the workflow. After that, Kanarra added a Conditional Node so that if the prediction is less than 75 percent nothing happens; but in every other case the workflow should notify someone about the prediction.
This logic can be expanded in many ways. Kanarra could use the Email Node to send an email to the administration of that hospital letting them know that maintenance will occur soon. Kanarra could also make this Edge Workflow more intelligent by storing the previous maintenance predictions in Workflow Storage. When a machine rises above 75 percent, it can check to see if a maintenance ticket was already created and if it was and the percentage grew from 75 percent to 85 percent then it can escalate the ticket, to let others know this will break sooner.
That’s how easy it is to enable predictive maintenance with TensorFlow on the edge with Losant. If you have any questions, we would love to hear from you in the Losant Forums.